
Enterprise voice data across India remains largely untapped because it is embedded in unstructured audio from calls, IVR systems, meetings, and voice applications. Converting it into usable text requires machine learning models capable of handling regional languages, dialects, background noise, and Hindi English code-switching.
When these models are weak or poorly optimised, digital platforms face operational friction across analytics, compliance, automation, and localisation. Speech recognition accuracy can drop nearly 25% in noisy or accented environments, directly affecting enterprise workflows.
In this blog, you’ll learn why speech-to-text machine learning is critical for converting complex Indian voice data into reliable, searchable text across enterprise systems.
At a Glance
- Actionable Voice Intelligence: Speech-to-text machine learning converts unstructured voice data into searchable enterprise intelligence.
- Built for India’s Linguistic Diversity: Indian speech recognition requires support for regional languages, accents, and code-mixed conversations.
- Accurate Transcription in Real-World Conditions: Deep learning models ensure reliable transcription in noisy and low-bandwidth environments.
- Enterprise-Grade Automation Enablement: Enterprise integration enables automation across analytics, compliance, and customer workflows.
- Foundation of the Voice-First Economy: Voice-driven systems will become a core digital interface in India’s connected economy.
What Does Speech-to-Text Machine Learning Mean?
Speech-to-text machine learning (ML), or automatic speech recognition (ASR), uses trained ML models to convert spoken audio into written text. These models analyse speech patterns, predict word sequences, and continuously learn from large volumes of audio to improve accuracy across diverse language contexts.
ML is essential for handling multiple languages and scripts, regional accents, code-mixed speech like Hindi-English, noisy call centre or IVR audio, and low-bandwidth telephony. It enables businesses to turn raw voice into actionable insights for search, analytics, automation, compliance, and multilingual engagement.
Now that we understand what speech-to-text machine learning is, let’s see how machine learning powers accurate, intelligent, and scalable enterprise speech-to-text.
Role of Machine Learning in Enterprise Speech-to-Text
Machine learning powers modern speech-to-text systems, ensuring reliable transcription across languages, accents, and real-world audio conditions. Traditional rule-based engines often failed with pronunciation variations, background noise, and diverse speaking styles, limiting their usefulness for enterprise-scale deployment.
Below are the key ways machine learning enhances transcription accuracy and intelligence for enterprises:
-
Deep Learning for Accurate Speech Recognition
Deep learning models learn directly from large and diverse speech datasets. Instead of relying on fixed rules, they identify complex speech patterns, allowing them to recognise regional accents, pronunciation differences, and speaking styles across Indian languages.
-
Neural Networks for Noisy and Low-Quality Audio
Neural networks are trained on millions of real-world voice samples, including call centre recordings, IVR audio, and mobile network speech. This training enables consistent transcription performance even when audio quality is degraded or network conditions are unstable.
-
Context-Aware Language Processing
Modern language models understand grammar, sentence structure, and word usage patterns. They help correct transcription errors, manage code-switched speech (e.g., Hindi-English), and adapt to domain-specific terminology used in banking, healthcare, automotive, and legal workflows.
-
Advanced Intelligence from Voice Data
Large-scale language models extend speech recognition into higher-level intelligence. They enable automatic summarisation, intent detection, sentiment analysis, and insight extraction, turning raw conversations into structured enterprise data.
Turn Voice Data into Actionable Insights with Speech-to-Text
Improve CSAT by up to 52% using Reverie’s enterprise-grade Speech-to-Text.
With the role of machine learning clear, let’s examine how these models operate within the speech-to-text pipeline.
How Speech-to-Text Works with Machine Learning
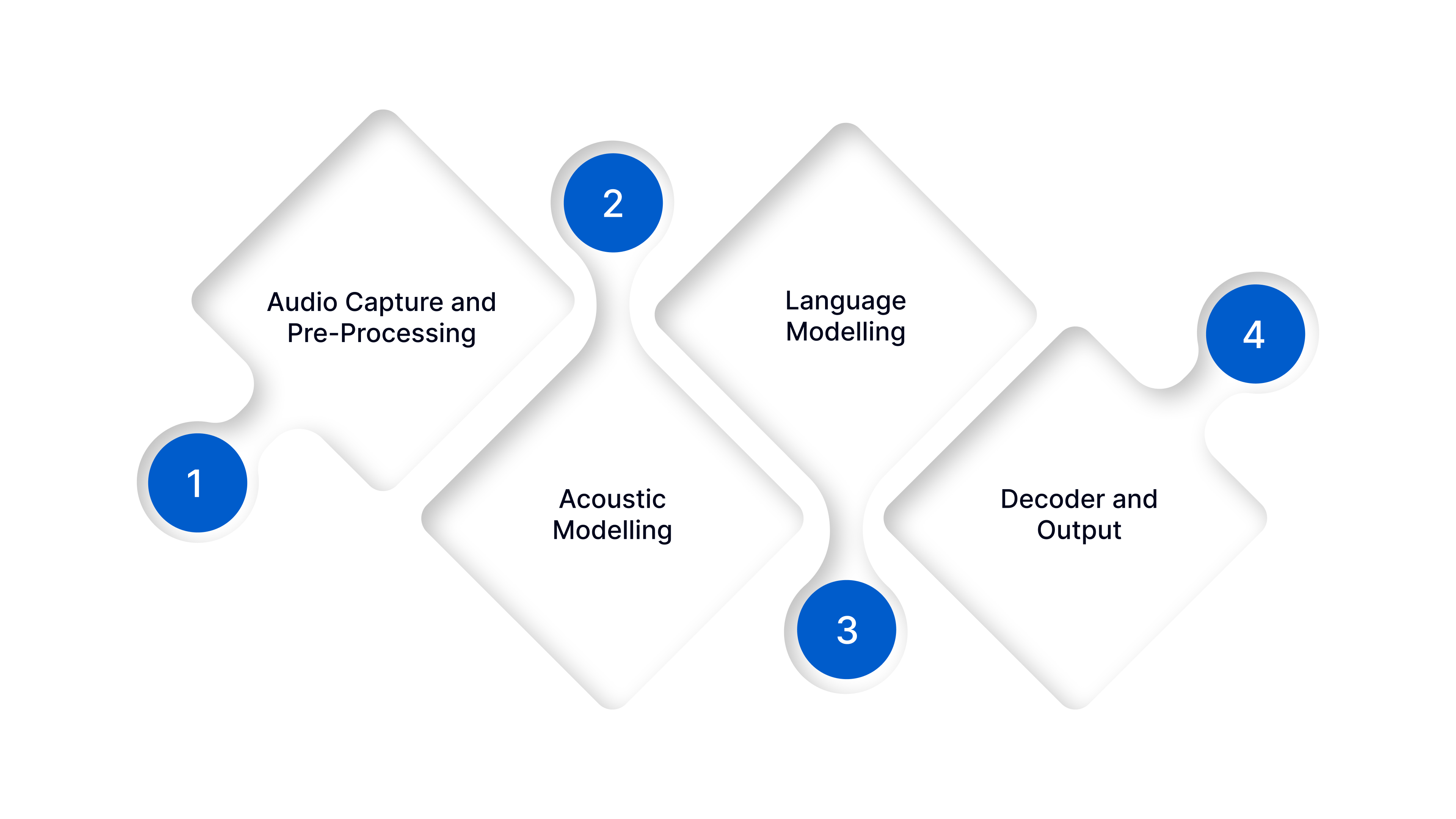
Speech-to-text systems use deep learning models trained on thousands of hours of speech data. These models learn how humans speak, pronounce words, and structure sentences. A typical speech-to-text pipeline includes the following stages:
1. Audio Capture and Pre-Processing
Audio comes from mobile and web apps, IVR and call centre recordings, in-vehicle voice systems, or uploaded files. The system removes background noise and normalises volume to ensure reliable transcription, even in noisy or low-bandwidth environments common in India.
2. Acoustic Modelling
Acoustic models convert raw audio into phonetic units. Deep neural networks analyse accents, regional pronunciations, and speaking speed, ensuring the system accurately recognises speakers across India’s multilingual population.
3. Language Modelling
Language models predict word sequences and correct grammar. For Indian enterprises, they must support multiple languages (Hindi, Tamil, Telugu, Kannada, Malayalam, Marathi, Bengali, Gujarati, Punjabi, Odia, Assamese, and English), code-switching, and domain-specific terminology. This ensures precise transcription for customer support, IVR, and analytics workflows.
4. Decoder and Output
The decoder combines acoustic and language predictions to produce the final transcript in real time or from recorded audio. The result is accurate, searchable text that can be integrated into business systems for analytics, automation, compliance, and multilingual engagement.
If your business needs a reliable speech-to-text solution, Reverie’s Speech-to-Text API is built to help. It supports real-time transcription across multiple Indian languages and dialects. Get started today!
Also Read: Speech SDK: Developer’s Guide to Speech Recognition
With accuracy and intelligence in place, here’s how enterprises can implement STT across digital platforms.
How to Implement STT Machine Learning in Your Digital Platform
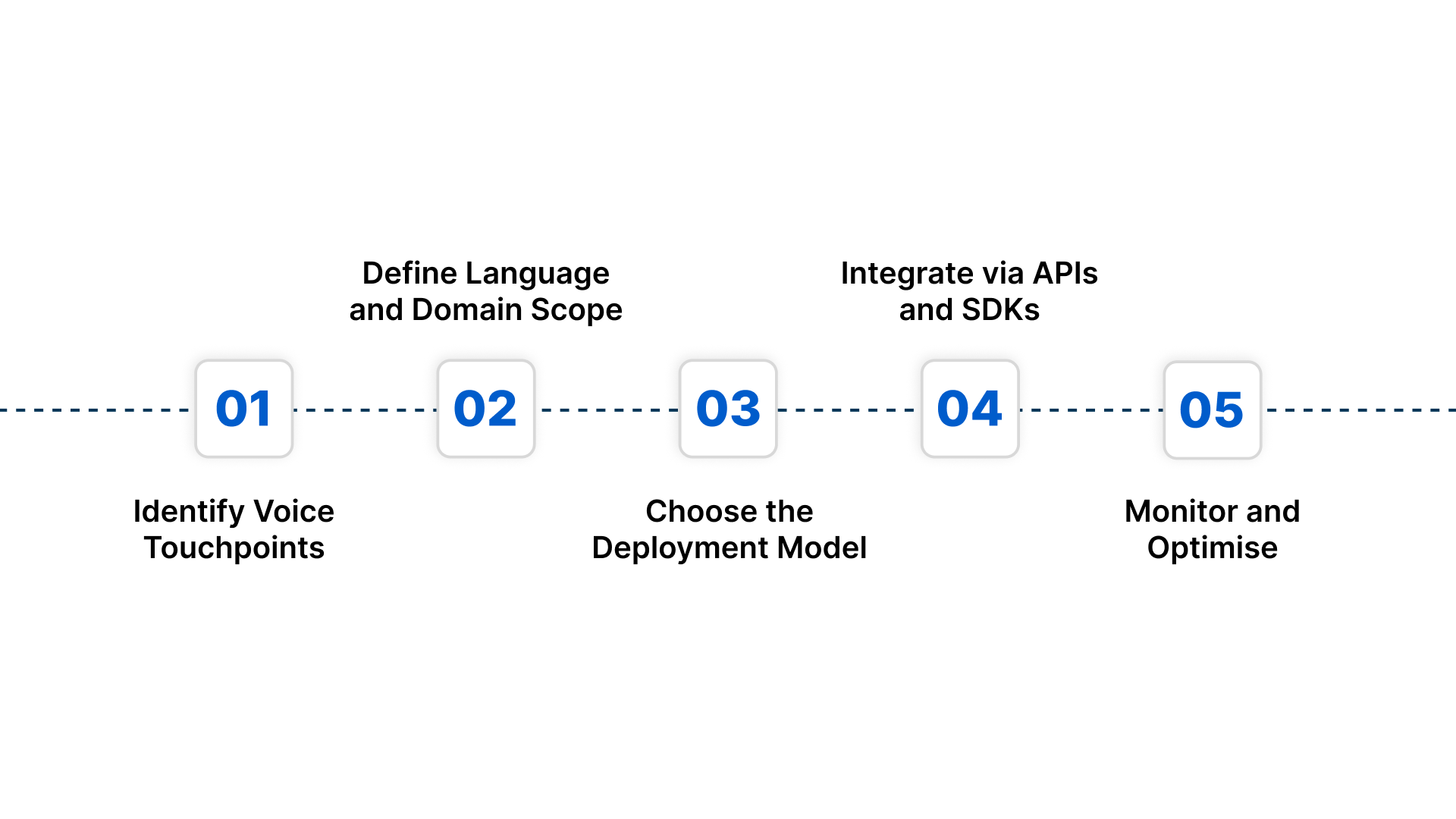
Enterprise speech-to-text implementation requires a structured and scalable approach to ensure accuracy, compliance, and seamless integration with existing systems.
Step 1: Identify Voice Touchpoints
Start by mapping where voice interactions already exist or can be introduced across your digital ecosystem, such as:
- Call centres and IVR systems
- Mobile applications
- Web platforms
- Voice bots and virtual assistants
- In-vehicle voice systems
This helps define the scope of transcription and the type of audio environments the system must support.
Step 2: Define Language and Domain Scope
Identify which Indian languages and dialects are required based on your user base. Determine whether domain-specific vocabulary is needed for industries such as banking, healthcare, automotive, or legal to ensure accurate transcription.
Step 3: Choose the Deployment Model
Select a deployment model based on data sensitivity, regulatory requirements, and infrastructure preferences:
- Cloud deployment for rapid scalability
- On-premise deployment for compliance and data control
- Hybrid deployment for flexible workload management
Step 4: Integrate via APIs and SDKs
Use developer-friendly SDKs and REST APIs to integrate speech-to-text capabilities into your applications. This enables real-time transcription, batch processing, and seamless workflow automation.
Step 5: Monitor and Optimise
Track transcription accuracy, usage patterns, and system performance through analytics dashboards. Continuous monitoring helps fine-tune language models and improve output quality over time.
Automate Workflows and Analytics from Voice Data
Reduce operational costs by up to 62% with Reverie’s Speech-to-Text APIs.
With implementation covered, the next step is to examine how speech-to-text machine learning will shape the future of digital experiences in India.
Future of Speech-to-Text Machine Learning in India
Voice is becoming the default digital interface for millions in India. With smartphones, connected vehicles, and digital infrastructure expanding, speech-to-text systems must handle diverse languages, accents, and real-world environments. Key developments include:
- Deeper support for regional dialects and local speech variations
- Smarter recognition of mixed-language conversations, such as Hindi-English and Tamil-English
- Emotion and intent detection from voice interactions
- Real-time translation and transcription across Indian languages
- Voice-driven automation across enterprise platforms
Early investment in scalable, language-ready speech systems positions organisations to lead in India’s voice-first digital economy.
Also Read: Power of Speech to Text API: A Game Changer for Content Creation
Now, let’s explore how a reliable solution like Reverie’s Speech-to-Text API improves workflow efficiency, transcription accuracy, and the integration of multilingual voice data.
How Reverie’s Speech-to-Text API Enhances Your Workflow?
An effective speech recognition system only delivers value when organisations can convert voice into actionable insights. Reverie’s Speech-to-Text API extends this capability, enabling your business to quickly transcribe audio from meetings, phone calls, podcasts, live streams, and other voice data.
Here’s how it enhances workflow efficiency, accuracy, and multilingual integration:
- Transcription in 11 Indian Languages: Seamlessly convert conversations, including regional or mixed-language content, into correctly punctuated text.
- Real-time and Batch Processing: Monitor calls live or process large volumes of audio later, giving you flexibility in how you analyse voice data.
- Voice Typing and Command Support: Enable users to create text by speaking or to invoke actions via voice commands.
- Smooth Integration and Developer Support: Use APIs or SDKs with clear documentation and a testing playground to integrate speech transcription into your CRM, contact center, or internal systems.
- Data Security & Privacy Compliance: Reverie encrypts data and adheres to strong privacy standards, essential for sectors such as legal, healthcare, and finance.
To scale efficiently, enterprises can use Reverie’s Speech-to-Text API to accurately capture speech, handle code-switching, and integrate seamlessly into workflows, turning calls, meetings, and podcasts into actionable text. Contact us to get started!
Conclusion
Speech-to-text machine learning transforms unstructured voice data into actionable enterprise insights. It enables accurate transcription across languages, accents, and noisy environments. By integrating into workflows, it drives analytics, automation, and improved decision-making.
To put these capabilities into practice, Reverie’s Speech-to-Text API integrates seamlessly into your digital ecosystem, supporting both cloud and on-premises deployments for scalability and flexibility. Its features include keyword spotting, profanity filtering, sentiment analysis, and smart analytics, all designed to enhance workflow efficiency and user experience.
Ready to utilise your speech recognition system for accurate, real-time voice insights? Sign up now and see how it can scale across your workflows.
FAQs
1. How does speech-to-text machine learning improve enterprise data governance?
Speech-to-text systems convert voice records into searchable text, enabling better audit trails, compliance tracking, and documentation. This ensures regulated industries such as banking and healthcare can maintain structured records from call logs, IVR interactions, and customer conversations.
2. Can speech-to-text systems support multilingual customer support teams?
Yes. Modern speech-to-text platforms support multiple Indian languages and code-mixed speech, allowing support teams to analyse conversations across regions, monitor service quality, and generate reports without manual translation or transcription.
3. How does speech recognition help in automating enterprise workflows?
Speech-to-text converts conversations into structured data that can trigger CRM updates, ticket creation, call summaries, and sentiment tagging. This reduces manual effort and enables faster response times across customer service and operations teams.
4. What factors affect speech recognition accuracy in Indian environments?
Accuracy depends on audio quality, background noise, accent diversity, language mixing, and telephony compression. Well-trained machine learning models tailored to Indian speech patterns are essential for consistent, reliable transcription.
5. Is speech-to-text suitable for real-time decision making?
Yes. Real-time transcription enables live call monitoring, instant keyword detection, and immediate sentiment analysis. This supports faster issue resolution, compliance checks, and proactive customer engagement.
