In the growing era of digitalisation, the demand for Indian language content is on the rise, with over 536 million users accessing the content in their local languages. The Indian-language translation ecosystem finds it challenging to manage such a large volume of content and translate it within a reasonable time.
Prabandhak, a cloud-based AI-powered translation management hub, aims to bridge the gap between India’s translation ecosystem and third-party APIs that don’t support Indian languages well.
Prabandhak is an automated, end-to-end translation management platform that helps translate high-volume digital content in 21 Indian languages and 53 International languages.
Prabandhak brings together all the players of the Indian-language translation ecosystem onto one platform: translators, language service providers, and enterprises. The platform provides complete transparency, accuracy, and control with the help of its real-time project management dashboard. Hence all the language players can easily manage large projects at scale and significantly increase their revenue.
Businesses can use the built-in marketplace to find individual translators and LSPs based on their budget, efficiency, and timelines. With superior translation technologies, the platform increases efficiency by automating translation and allowing them to execute projects up to four times faster.
Prabandhak’s unique features:
- Go to market 40% faster than manual translation with neural machine translation specifically trained on Indian languages.
- Work with all entities on one single platform with a real-time collaboration hub.
- Eliminate manual file transport and coordination with secure, centralised data management.
- No more follow-ups through emails/calls with a real-time project and resource tracking system.
- Reduce cost, effort, and turnaround time with a reusable, Indian-language specific translation memory and base.
- Quickly and accurately translate documents with Indic spell checker and glossaries with the inbuilt CAT tool for Indian languages with automated QA.
- Say no to manual DTP and DTP-related costs with auto recompilation of files.
- Post your requirements on the marketplace and work with competent LSPs and freelance translators in the collaborative marketplace for Indian languages.
What is new in Prabandhak AI V2.0?
Prabandhak goes international
Prabandhak V2.0 currently supports 53 international languages. The newly supported International languages are:
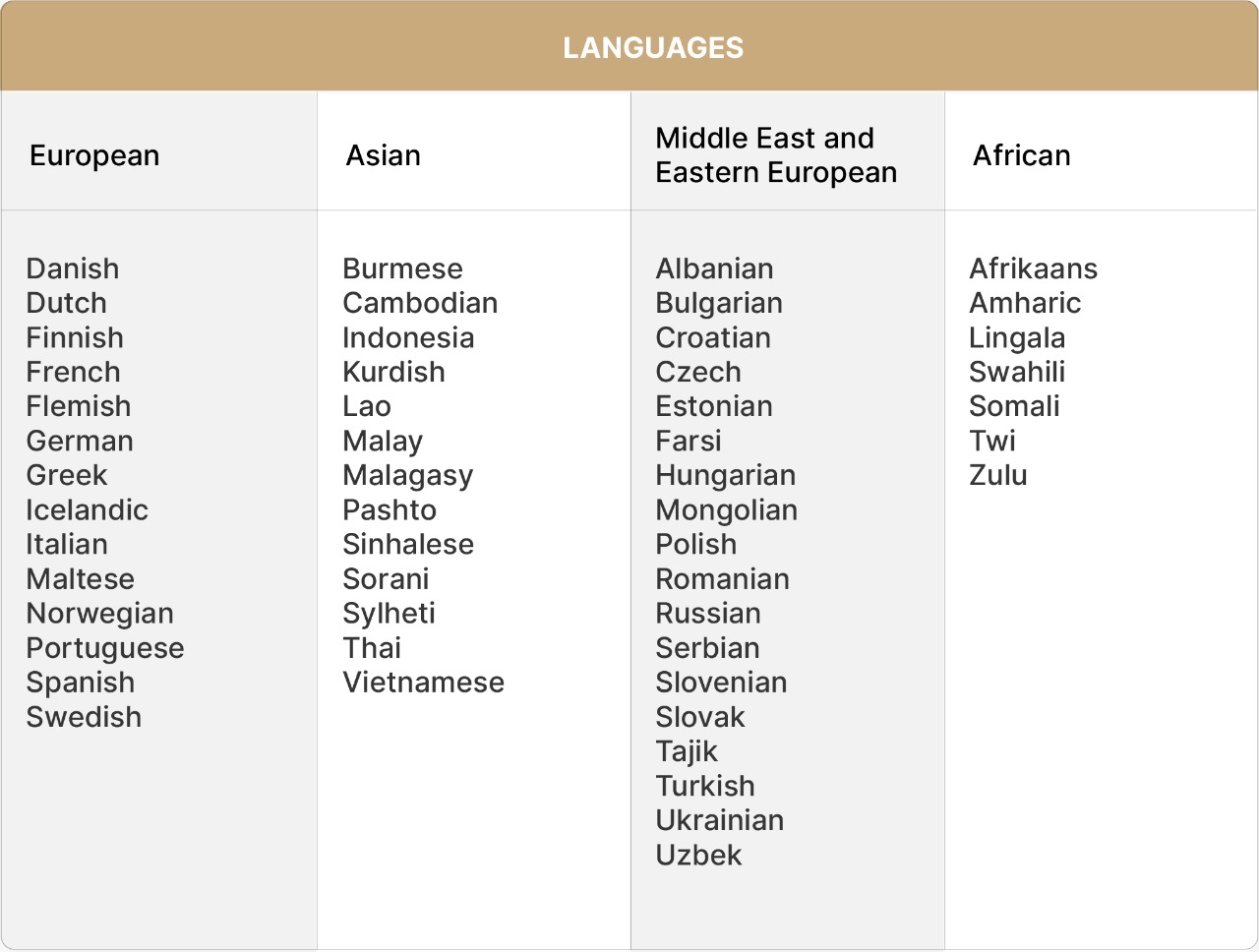
There was an increase in demand for international language translation capabilities since many LSPs on the Prabandhak platform also managed global projects.
These LSPs were required to switch between two platforms: one for Indian language translations and another for international language translations. It was inefficient and cumbersome to switch between platforms and manage two separate software licenses. In order to ensure a seamless translation process on a single platform, the addition of new international languages has been released.
More Indian languages added
Prabandhak V2.0 now supports all official 21 Indian languages. By adding more languages, the platform ensures an increase in reaching larger audiences, building trust, and attracting new customers for enterprises, language service providers, and freelancers (translators).
Although Prabandhak V1.0 supports 11 major Indian languages, including Tamil, Telugu, Kannada Malayalam, Odia, Assamese, Bengali Gujarati, Marathi, and Punjabi. With the inclusion of new languages, users or customers are now fully equipped to work on multilingual projects on a single platform.
Improved NMT suggestions from English to 11 Indian languages
Machine learning algorithms require high-quality and quantity of data to produce accurate results. It’s challenging to train translation models with minimal data. Thus by adding robust data preparation and augmentation pipeline helped the platform achieve higher translation accuracy and fluency. This aided the platform to provide improved neural machine translation (NMT) suggestions from English to the 11 most commonly used Indian languages.
These NMT suggested words or segments are more precise and fit better into the translated sentence, enabling translators to improve the quality and accuracy. Hence there are fewer post-editing, and translators can fine-tune translations to fit their language styles on the Prabandhak platform. The improved NMT suggestions help LSPs and translators to manage large projects easily with:
- Faster turnaround times and handling of a higher number of words.
- Increased accuracy and minimal post-editing efforts.
- High consistency as terminologies are consistently applied.
In short, with improved NMT suggestions, all language players on the Prabandhak platform benefit from faster delivery with better and more accurate translations.
NMT support from 11 Indian languages to English
The translation accuracy is improved by the increased size of parallel corpus data (i.e., structured set of translated sentences between two languages ) used for training. The larger the size and quality of the training corpus, the better is the translation.
With the availability of high-quality parallel corpus data, the NMT system was well trained for automatic translation from 11 Indian languages to English, as well as for the reverse model (i.e., supports machine translation from English to 11 Indian languages as well). Thus allowing translators to leverage this feature when working for back translation project.
Language-wise effective word count
Prabandhak reduces the translator’s efforts by decreasing the volume of content that needs to be translated intelligently. This is done by templatizing factual data like numeric, URLs, dates and then performing a duplicate check, further applying language-wise translation memory. As a result, translators can achieve consistency with fewer word counts and more efficiency while maintaining 100% effective translations.
Take an example of two small sentences: “My birthday is on March 6, 1990,” and “My birthday is on July 19, 1990.” Both the statements are identical, and by masking the dates here, ‘March 6, 1990’ and ‘July 19, 1990, the system will recognise the string as “My birthday is on” with a date placeholder.
Let’s say this particular sentence was found in a word document that had been entered into the system for translation from English to Hindi. Now comes the next project, which entails translating the same sentence from English to Hindi, Bengali, and Tamil. Since this sentence has already been translated into Hindi because of earlier translation, the effective word count for Hindi will decrease, but it will be different for the other two languages.
Since the effective word count gets measured by removing duplicates and applying language-wise translation memories. This feature helps project managers and administrators to see accurate language-wise words available for allocation through an analytics report. As a result, they can reduce cost while also improving the accuracy of their work allocation and tracking.
Improved glossary builder and management
One of the key features of Prabandhak V2.0 is the glossary builder and management, which includes a detailed list of:
- Terminologies,
- References,
- Industry or domain-specific unique nomenclature.
Translators can use it as a guide to ensure continuity throughout the translation with less time spent, better quality, and faster time to market.
In Prabandhak V2.0, when a source file is uploaded to the glossary builder, it uses artificial intelligence to parse the most prominent terms. With the help of a glossary term finder (an algorithm), it identifies the most important terms that can be translated into terminologies or glossaries for translation projects.
Take, for example, the following sentence: “I would like to travel from Delhi to Mumbai on the 15th of April 2021.” The glossary finder will intelligently identify Delhi and Mumbai as city names and make them available as glossary terms. These types of terms are discovered and then translated or standardised using transliteration or translation or left unchanged if required.
Translators can reuse such glossary terms. Each time a defined term appears while on projects, it is used consistently and correctly. If any translator working on the project does not use the project creator’s predefined standardised term, the system issues a warning.
For example, consider you a language service provider working on a travel project, and your source file contains a list of city names. When you upload the source file to the glossary finder, you will get a list of city names along with their addresses. You can easily transliterate them, get them verified, and add them to your Prabandhak account as a glossary.
Let’s say you’re uploading a project and assigning it to three translators. Each of them is responsible for translating 300 words in the same language. You will attach the list of city names to glossary with standardised transliteration while uploading the project. During the translation process, wherever city names appear, the system will automatically prompt to use the term mentioned in the attached glossary.
If these three translators, for example, come across the term “Delhi” in their statement, the system would prompt them to use the word from the glossary. If there is a mismatch in the word, such as incorrect spelling of “Delhi” compared to what is mentioned in the glossary, the system will issue a warning.
Suppose the translation project is distributed among hundreds of translators along with the glossary management; all the translators will use standardised transliteration for city names. In that case, LSPs can assure consistency in translations.
The improved glossary builder and management assist all translators by maintaining consistency in their translations. Thus allowing LSPs, customers, and project creators to speed up and save time during the translation process.
Translation memory filters
A translation memory (TM) file is a structured file that stores translation and linguistic data. The translation memory file format that Prabandhak supports is .TMX. When a new .TMX file is uploaded to the Prabandhak platform; it allows to tag the file with a particular domain or client. The translation memory filters make it easy to segregate client or domain-specific TMs.
For example, a translator is working with several clients and receives a project from client A. The translation memory filters make it easy to segregate client-specific TMs. The translator can easily apply client A’s translation memory, which contains a collection of instructions and translation style, thus maintaining consistency in translation quality.
Let’s say a translator is looking for the translation memory for the healthcare industry. When working on healthcare projects, the translation memory filter allows to find and apply most of the available domain-specific TMs easily.
Improved CAT tool features
The Prabandhak V2.0’s CAT tool has improved features like:
- Autosave as a draft,
- Enhanced filter for segment search,
- NMT and transliteration suggestions,
- Automatic QA/QC,
- Quick find and replace options, and more.
These enhanced built-in features allow translators to maintain consistency while producing higher-quality translations and increase translation speed and performance.
One of the challenges that translators faced was moving from one segment to the next. They had to manually save their changes by clicking on the file. The new feature saves the translator’s changes in the drafts automatically, ensuring that they do not lose their work.
Also, the enhanced filter option provides details such as;
- Segments matched from the translation memory,
- Translated segments,
- Edited segments,
- Proofread segments,
- Assigned strings that are blank, and so on.
As a result, translators can see the current status of their allocated strings in real time.
Since this is a single web app, translators sometimes lose track of how many pages or segments they’ve translated. For example, if the translator has 1000 sentences to translate, the system would display 10 sentences on a single page, resulting in 100 pages. Let’s assume while translating they came across network failure or an accidental page refresh or unintentional logging out of the system. In such cases, translators might find it difficult to remember where they left off when they reopen the same project. The CAT tool’s auto remember function redirects translators back to their last edit.
The enhanced Neural Machine Translation (NMT) and transliteration suggestions improve the overall quality of the projects. When translators open a segment for translation, the machine translation suggestions get populated. Translators can easily pick relevant terms, thus ensuring overall consistency throughout the project.
The built-in QA/QC process in the CAT tool has been enhanced with the addition of a new set of rules for certain languages which is extremely helpful in removing false positives. The apostrophe, for example, is not a character in Indian language. Many languages use a ruthva comma, which is similar to an inverted comma but has a completely different purpose. It is used to elongate the last phonem (i.e.,a smallest unit of sound or pronunciation that distinguishes one word from another in a particular language).
The CAT tool’s “Find and Replace” feature has been upgraded to make it much quicker, so the screen now appears in milliseconds instead of the 10 to 15 seconds it used to take.
Overall, the enhanced CAT tool features improve translation quality in terms of accuracy, quality, flexibility, and speed.
Multiple file uploads for proofreading
There are five types of translation pipelines in V2.0:
- Translation only: This means the source file is translated only once.
- Translation and proofreading: This means the source file is translated once and proofread once, thus adding one layer of verification.
- Translation with proofreading and editing: This means the source file is translated once and has two verification layers over it.
- Proofreading.
- Proofreading and editing.
The first three (1 to 3) pipelines can be applied only on the source file and not on the bilingual or multilingual files. The last two pipelines (4 & 5) are applied either on bilingual or multilingual files.
Since the pipelines start from proofreading, the tasks necessitate that the source file should be bilingual or multilingual along with the translations that are supposed to be proofread.
Previously, the platform supported only excel formats; hence the translators had to convert them to a system-specific format before uploading. The new feature allows the translator to upload multiple file formats that support the standard proofreading file, such as TBX and TMX.
Translation memory can be applied to projects at all levels
The translation memory (TM) is used at all stages of a project in Prabandhak V2.0. It also allows translators to use their translation memories, resulting in a more effective and high-quality translation process.
In Prabandhak V1.0, the translators were limited to using the system’s translation memories. If they have their own translation memories for the project, they didn’t benefit from applying them, which resulted in more translation and post-editing time.
For example, Sam has worked on a travel domain, and he is outsourcing his project to two translators Ryan & Kate. Sam creates the project; hence his translation memory gets applied to the project. The two translators also have extensive experience working on travel projects, and they have their own translation memories developed while working with their own independent clients.
In Prabandhak V1.0, only the project creator’s translation memory can be applied to the project. When the projects were outsourced to translators, they were not allowed to use their own translation memories. They continue to translate using the available translation memories, resulting in a significant increase in translation time.
By gaining a better understanding of such challenges, Prabandhak V2.0 introduced a feature that allows translators to use their own translation memories on any project without compromising their privacy.
With this feature comes along benefits like:
- Increase in consistency throughout the content and cuts down on editing.
- Increase in translator productivity by up to 40%.
- Access to more than one translation memory at once with no restriction.
- Saving cost and enabling faster turnaround times with 100% TM match.
- Controlling own translation memories in real-time with full transparency.
- Faster time to market due to less time spent on translation.
Translators can achieve more in less time by using the translation memory at all levels, giving editors and reviewers an advantage by receiving accurate and consistent documents.
Enhanced data security features
As the amount of sensitive data flow expands, it’s more important than ever to protect data confidentiality and sensitivity.
Prabandhak V2.0 creates a secure environment by allowing project creators to configure data security features that enable or disable translators from downloading source or target files. In addition, for every server interaction or network call that happens over HTTPS, project creators can prevent translators from downloading those files or data.
The entire communication between the client and the server is encrypted end-to-end, and all data is secured with an API key such that any unsecured request will be automatically rejected.
In closing
Prabandhak V2.0’s latest features and enhancements were developed to aid India’s translation industry in achieving reliability, scalability, transparency, accuracy, and process standardisation. Through its real-time project management dashboard, all language players gain full visibility and control on this unified platform, giving them easy visibility of timelines, costs, and accuracy.
With Prabandhak V2.0, businesses can adapt to an intelligent translation management system that relies more on automation. Get your translation process simplified by seamlessly connecting to Prabandhak, an AI-powered translation management hub.
