
Ever listened to a long meeting or customer call and wished you could instantly tell who said what?
Accurate transcripts play a pivotal role in preserving business conversations from legal proceedings to customer support calls. They create a written record that is searchable, referable, and ready for analysis, improving compliance, accessibility, and decision‑making.
However, even the best transcripts can lose vital context if you don’t know which speaker said what. That’s where Speaker Diarization comes in. It automatically recognises and labels individual speakers, adding clarity and structure to each segment of a transcript.
This blog explores what speaker diarization is, how it works, and how it enhances transcription accuracy and business insights across industries such as banking, media, healthcare, e-commerce, and legal services.
Key Takeaways
- What It Is: Speaker diarization automatically separates and labels individual speakers in audio recordings, enabling you to identify who said what in multi-speaker conversations.
- How It Works: The process involves several stages, including speech detection, segmentation, voice embedding, clustering, labelling, transcription, and attribution, which assign each spoken segment to the correct speaker.
- Why It Matters for Businesses: It improves transcript readability, reduces manual review effort, and supports compliance and audit trails across meetings, calls, and service interactions.
- Common Use Cases: These include legal, healthcare, media, education, and banking, for accurate documentation, training, dispute resolution, and regulatory reporting.
- How to Measure Accuracy: Diarization quality is measured using the Diarization Error Rate (DER). A lower DER indicates more accurate speaker separation and fewer manual corrections.
- Key Challenges: Limitations include overlapping speech, poor audio quality, similar voices, and short speaker turns, all of which may impact diarization accuracy.
What is Speaker Diarization?
Speaker diarization is the process of identifying and separating individual speakers within an audio stream so that each person’s speech is clearly grouped and labelled in the automatic speech recognition (ASR) transcript. In simple terms, it helps you know who spoke when by analysing each speaker’s unique voice characteristics and clustering their utterances together.
This feature is highly valuable when dealing with recordings that include multiple participants, such as client meetings, patient consultations, or customer support calls. It ensures your transcripts are not only accurate but also structured, readable, and easy to analyse.
Example without speaker diarization:
Good morning. Thank you for calling Horizon Bank. How may I assist you today? Hi, I wanted to check the status of my loan application. Sure, may I have your application number, please? Yes, it’s 4572A. Thank you. Please hold for a moment while I retrieve your details.
Example with speaker diarization:
[Speaker:0] Good morning. Thank you for calling Horizon Bank. How may I assist you today?
[Speaker:1] Hi, I wanted to check the status of my loan application.
[Speaker:0] Sure, may I have your application number, please?
[Speaker:1] Yes, it’s 4572A.
[Speaker:0] Thank you. Please hold for a moment while I retrieve your details.
With speaker diarization, your transcript shifts from a single block of text to a well-structured conversation, where each speaker’s input is clearly defined. This clarity helps your teams track dialogue flow, attribute statements correctly, and extract meaningful insights.
To make this possible, speaker diarisation follows a structured process that separates and labels each voice in the audio stream.
Also Read: What is ASR: Full Form and Its Significance in Voice Technology
How does speaker diarization work?
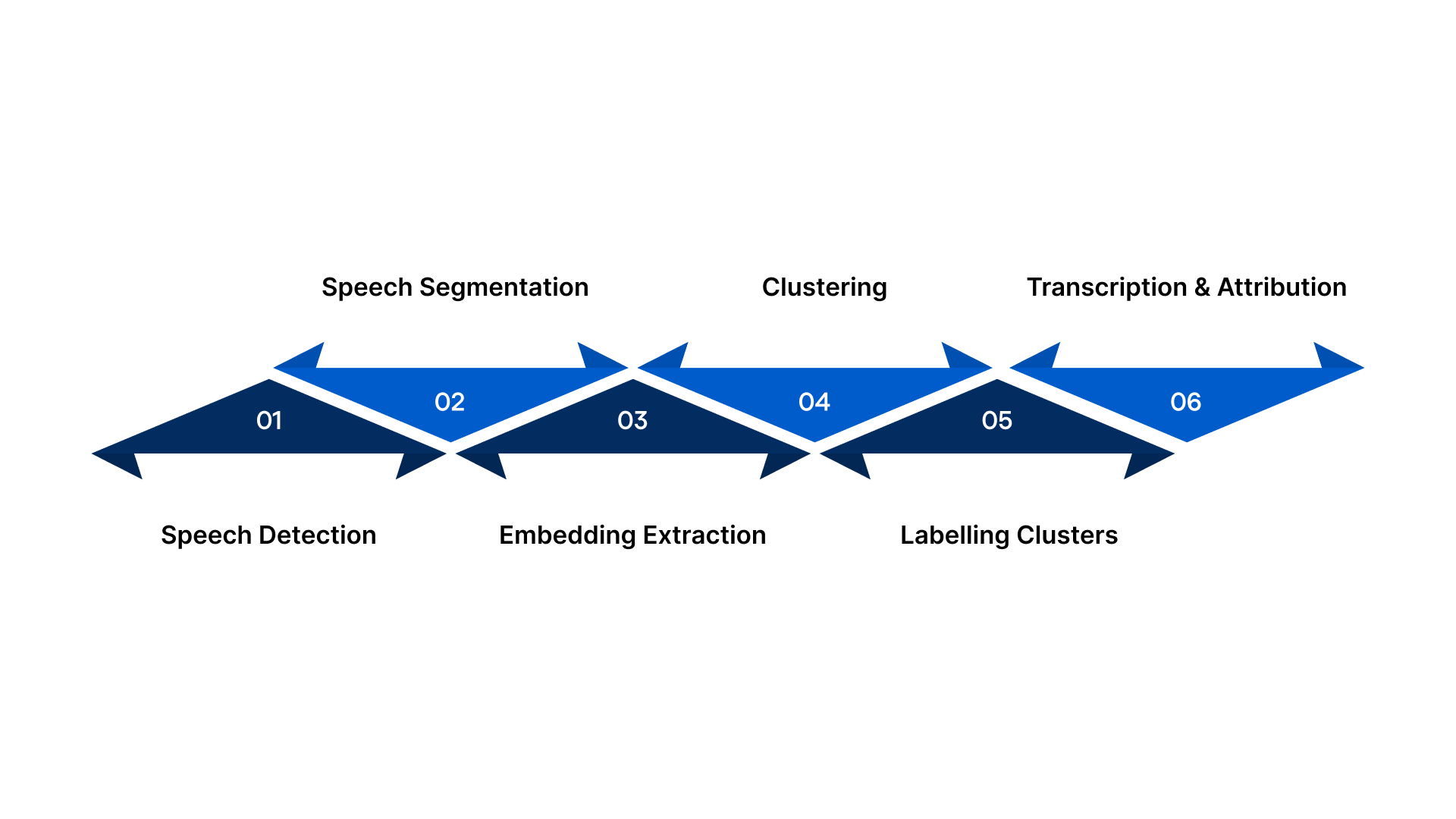
Speaker Diarization consists of several structured stages to ensure that each portion of an audio stream is accurately attributed to the correct speaker. These key processes form the core of how Diarization systems function in practice.
Here is a step-by-step breakdown of the technical workflow behind speaker Diarization:
1. Speech Detection
First, the system detects where there is speech and where there is silence or background noise in your audio. This means the system ignores hold music, long pauses, and irrelevant noise, focusing only on the actual conversation between participants.
2. Speech Segmentation
Next, the detected speech is broken into smaller segments based on changes in the audio signal. Each time the system senses a change in voice or speaking pattern, it marks a boundary. This is where the conversation starts to get divided into meaningful chunks that can later be linked to specific speakers.
3. Embedding Extraction
For every segment, the system creates a numerical “fingerprint” of the voice, called an embedding. This fingerprint captures the unique characteristics of each speaker’s voice tone, pitch, and speaking style without storing the actual content as plain audio. This enables the system to efficiently compare and group similar voices at scale.
4. Clustering
These voice embeddings are then grouped into clusters, where each cluster ideally represents one speaker. In practical terms, all segments that sound like Speaker A are grouped together, all that sound like Speaker B go into another group, and so on. This step is crucial when you have multiple participants on a call, in a consultation, a panel discussion, or a meeting.
5. Labelling Clusters
Once the clusters are formed, the system assigns them labels, such as Speaker 1, Speaker 2, and so on. You can then map these neutral labels to real roles, for example, Agent/Customer in a contact centre or Moderator/Panel Member in media and events.
6. Transcription and Attribution
Finally, convert the labelled segments into text using a Speech-to-Text application or a speech recognition system. This step of transcription leverages advanced Speech-to-Text systems, which convert audio segments into text.
These systems utilise deep learning models trained on extensive datasets to recognise and transcribe spoken language accurately. By attributing each text segment to the correct speaker, these systems enhance the clarity and readability of the final transcript.
With Reverie Speech‑to‑Text API, you can leverage cloud‑based or on‑premise deployment options, support for 11 Indian languages plus English, and robust speaker‑labelling functions. Our speech-to-text API solution identifies speakers based on the training set, enabling speaker-specific data extraction.
With a clear understanding of how the process functions, it’s essential to know where speaker diarization delivers the most value in real-world applications.
What Are the Common Use Cases for Speaker Diarization?
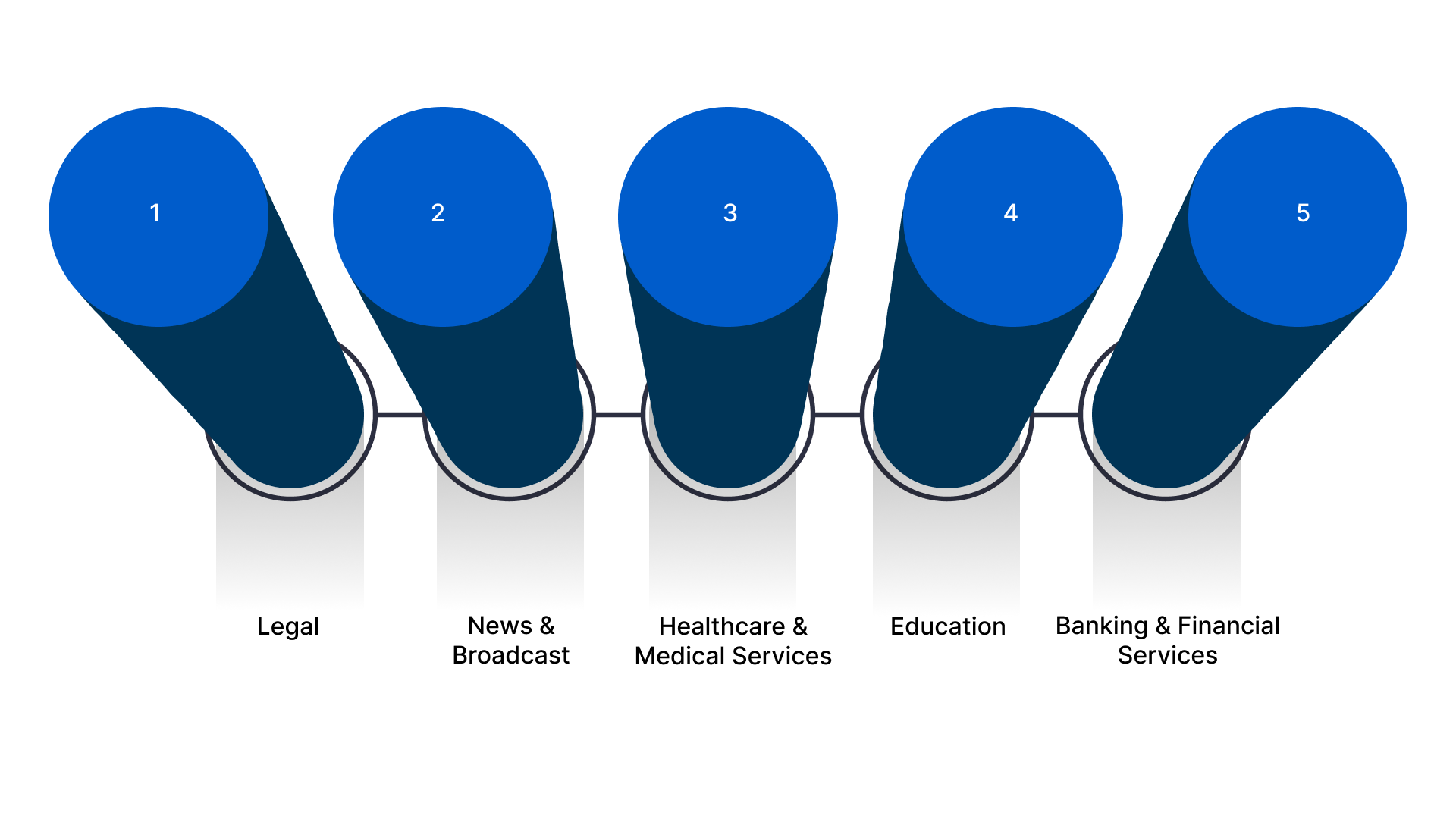
Speaker diarization is useful whenever multiple people are speaking and you need a clear, structured record of who said what. Across legal, healthcare, media, banking, and even internal meetings, it helps you convert raw recordings into transcripts ready for review, compliance, and analysis.
Instead of manually figuring out speakers, your teams get clean, labelled conversations they can act on. Here are some of the most common and practical use cases where you can apply speaker diarization in your organisation:
1. Legal
In legal fields, accuracy and attribution are critical. With speaker diarization, you can:
- Separate statements from different parties in depositions, client meetings, witness interviews, and internal review calls.
- Clearly attribute each line in the transcript to the right person (for example, judge, lawyer, client, witness).
- Speed up case preparation, documentation, and audit trails, as your team no longer has to replay audio to verify who spoke.
- Strengthen compliance and risk management, as every key statement is traceable to a specific speaker.
This is especially useful if you handle high volumes of recorded calls or proceedings and need reliable, speaker-labelled transcripts for reference and evidence.
2. News and Broadcast
If you operate in media, news, or digital content, diarization helps you manage crowded audio environments:
- Automatically separate anchor, reporter, panellists, and guests in panel discussions or debate shows.
- Make post-production easier by allowing your editorial team to quickly locate specific speaker segments for quotes or highlights.
- Support multilingual or regional content that includes multiple voices and languages in the same recording.
- Enable the faster creation of subtitles, summaries, and digital archives, thereby enhancing searchability and content reuse.
This enables you to maintain consistency, reduce manual effort, and derive greater value from your audio and video assets.
3. Healthcare and Medical Services
In healthcare, speaker diarization can support better documentation and patient care:
- Distinguish between doctor, patient, and attendant in consultations, telemedicine sessions, or case discussions.
- Produce clearer clinical notes where it is obvious which inputs came from the clinician and which from the patient.
- Improve accuracy in diagnosis notes, treatment explanations, and consent discussions, especially when recordings are reviewed later.
- Help with multilingual interactions, where the patient may speak one Indian language and the doctor another, or both in English.
This reduces the burden on doctors to document everything manually and gives your organisation more reliable records for continuity of care and compliance.
4. Education
In education and training environments, speaker diarization helps you structure learning interactions:
- Separate speech from instructors, students, and guest speakers in classroom recordings, online lectures, webinars, and doubt-clearing sessions.
- Make it easier to review Q&A segments, as you can quickly see which questions came from which participant.
- Use labelled transcripts as learning material, allowing learners to follow discussions more clearly.
- Support training programmes, internal academies, and skill-building initiatives across your organisation.
For institutions and enterprises running large-scale training, this makes your content far more useful for revision, assessment, and knowledge management.
5. Banking and Financial Services
In banking and financial services, diarization directly supports compliance, customer experience, and risk management:
- Clearly separate agent and customer speech in contact centre calls, loan discussions, and complaint handling
- Attribute specific statements during KYC calls, dispute resolution, and collections to the correct speaker.
- Support audit and regulatory reviews with speaker-labelled transcripts that show who confirmed what and when.
- Enable better quality monitoring and training, as supervisors can track how agents handle sensitive conversations and commitments.
This makes your voice data a more reliable evidence source and a more useful tool for improving both compliance and customer service.
Implementing diarization is only part of the process; measuring its accuracy is what determines its real impact.
Also Read: 10 Best Speech-to-Text APIs for Real-Time Transcription
How to Evaluate a Speaker Diarization Quality
When measuring diarization quality, the standard metric is the Diarization Error Rate (DER). It informs you, throughout the entire duration of your audio, which share was handled incorrectly. This means either speech was detected where there was none, real speech was missed, or speech was attributed to the wrong speaker.
Formula:
DER = (False Alarm+Missed Detection+Confusion) / TOTAL
Here are the components you should understand and track:
- False Alarm: Speech predicted where there is no speech (e.g., background or hold music flagged as speech). In your reviews, this inflates transcripts and wastes analyst time.
- Missed Detection: Real speech that the system fails to detect. This creates gaps in your record, which can be risky for compliance, audits, or medical/legal documentation.
- Confusion: Speech detected but assigned to the wrong speaker (e.g., customer lines tagged as agent). This directly harms the accuracy of “who-said-what” and weakens the value of evidence.
- Total (Denominator): The total scored duration of your reference audio (usually excluding long non-scored segments). DER expresses total diarization error as a proportion of this duration.
A DER close to 0 means the diarization is highly accurate. A higher DER means more mistakes in detection or attribution. A lower DER means fewer manual fixes and faster reviews. A perfect system would have DER = 0.
While measuring quality is essential, it’s equally important to recognise the practical limitations that can impact the overall performance.
The Limitations and Challenges of Speaker Diarization
While speaker Diarization can bring immense value across various operations, including legal, healthcare, banking, media, and e-commerce, it is not without its constraints. Knowing these upfront helps you set realistic expectations and plan for mitigation.
Here are the main challenges you should consider:
- Overlapping speech/cross-talk: When multiple people speak simultaneously or interrupt one another, diarization systems struggle to separate voices accurately.
- Poor audio quality and background noise: Recordings from noisy environments, low-quality microphones, or distant speakers reduce the system’s ability to distinguish individual voices accurately.
- Short speaker turns or minimal speech: If a speaker only speaks for very short durations, the system may fail to recognise them as a separate voice and may merge their speech with someone else’s.
- Similar voice characteristics or accents: When speakers have very similar tones, accents, or speech patterns, clustering and labelling may become inaccurate.
Despite these limitations, speaker Diarization still delivers significant value when applied in the right conditions. By understanding its constraints, you can better align it with your business needs and ensure more reliable outcomes.
Conclusion
Speaker Diarization helps you convert complex audio recordings into structured, speaker-labelled transcripts. It enhances accuracy, supports compliance, and streamlines analysis across key sectors, including legal, healthcare, banking, media, and e-commerce.
If you’re looking to implement speaker Diarization at scale, Reverie’s Speech-to-Text API offers built-in speaker labelling capabilities alongside real-time and batch transcription support. We support multiple Indian languages, integrate seamlessly with enterprise systems, and provide highly accurate ASR outputs enriched with punctuation, sentiment analysis, and speaker separation.
Here’s why Reverie’s Speech-to-Text API supports:
- Accurate Speech Recognition: Delivers high transcription precision, reducing errors and manual correction.
- Multilingual Support: Supports Indian English and 11 Indian languages, ideal for regional operations.
- Customisable Language Models: Recognises domain-specific terms in legal, medical, or financial contexts.
- Real-Time Transcription: Processes live audio instantly, enabling immediate access to conversation data.
- Speaker Identification: Automatically labels and separates speakers in transcripts for clarity and audit use.
- Secure and Reliable Integration: Meets enterprise-grade data privacy standards with easy SDK/API integration.
Ready to bring clarity to your voice data? Sign up with Reverie and transform conversations into actionable business insights.
FAQs
1. Can speaker diarization work without knowing how many speakers there are in the audio?
Yes, many modern diarization systems estimate the number of speakers automatically, so you don’t need to specify the count in advance.
2. How accurate is speaker diarization in real‑world enterprise use?
Accuracy depends on factors like audio quality, overlapping speech, number of speakers, and language/accent diversity. Accuracy is often measured by the Diarization Error Rate (DER).
3. Can I specify or limit the number of speakers in the recording to improve accuracy?
Yes, many diarization solutions allow you to set “max_speakers” or specify that there are ‘N’ speakers, which can improve accuracy in complex audio environments.
4. How do systems handle overlapping speech?
Overlap is hard; some systems detect and assign overlaps to multiple speakers or use neural models that explicitly model simultaneous voices, but errors remain higher for overlap.
5. What features does a system extract from audio?
Systems commonly use short-term spectral features and summarise them into speaker embeddings such as i-vectors, d-vectors, or x-vectors.
