
In 2026, multilingual accuracy is the real benchmark for speech-to-text systems, especially in India. In independent voice-agent tests, Reverie’s India-trained STT model recorded ~4.2% higher accuracy and 1.5× faster response times than Deepgram, especially on “Hinglish,” number recognition, and regional names. With 3+ million API calls processed and live use in BFSI call-center workflows, these differences are already shaping real business outcomes.
As global STT providers expand into Indian markets, the gap between English-first models and India-trained systems is becoming clearer. Indian speech is rarely clean or single-language. It’s mixed, accented, and often delivered over noisy telephony channels.
This blog compares Deepgram multilingual accuracy vs Reverie in 2026, looking beyond headline claims to how both perform on Indian languages, code-switched speech, and enterprise voice use cases that matter in practice.
At a Glance
- Reverie’s India-trained STT is ~4.2% more accurate and 1.5× faster than Deepgram on Hinglish, numbers, and regional names.
- Deepgram offers global language coverage and low-latency models, ideal for worldwide voice AI applications.
- Reverie supports 11+ Indian languages with dedicated models and handles code-switched speech like Hinglish reliably.
- Indian enterprises benefit from Reverie’s telephony-grade audio handling, domain-specific vocabulary, and real-time + batch transcription.
- Reverie provides cloud and on-prem deployments, API analytics, and interactive testing tools for fast evaluation and enterprise-scale integration.
Reverie’s Capabilities in 2026: What Makes It Stand Out?
Reverie’s Speech-to-Text API is built from years of India-specific language research and optimised for real-world multilingual speech scenarios that global systems often struggle with.
At its core, Reverie supports broad Indian language coverage with dialect-aware models that recognise not only standard Hindi and English but also code-switched speech like Hinglish, regional pronunciations, and variations in accent that are common across Indian users.
Unlike many global STT providers, which are primarily trained on English-centric datasets, Reverie’s model family includes purpose-trained models for languages such as Bengali, Marathi, Tamil, Telugu, Kannada, Malayalam, Gujarati, Punjabi, Assamese, Odia, and more, each tailored to that language’s unique speech characteristics.
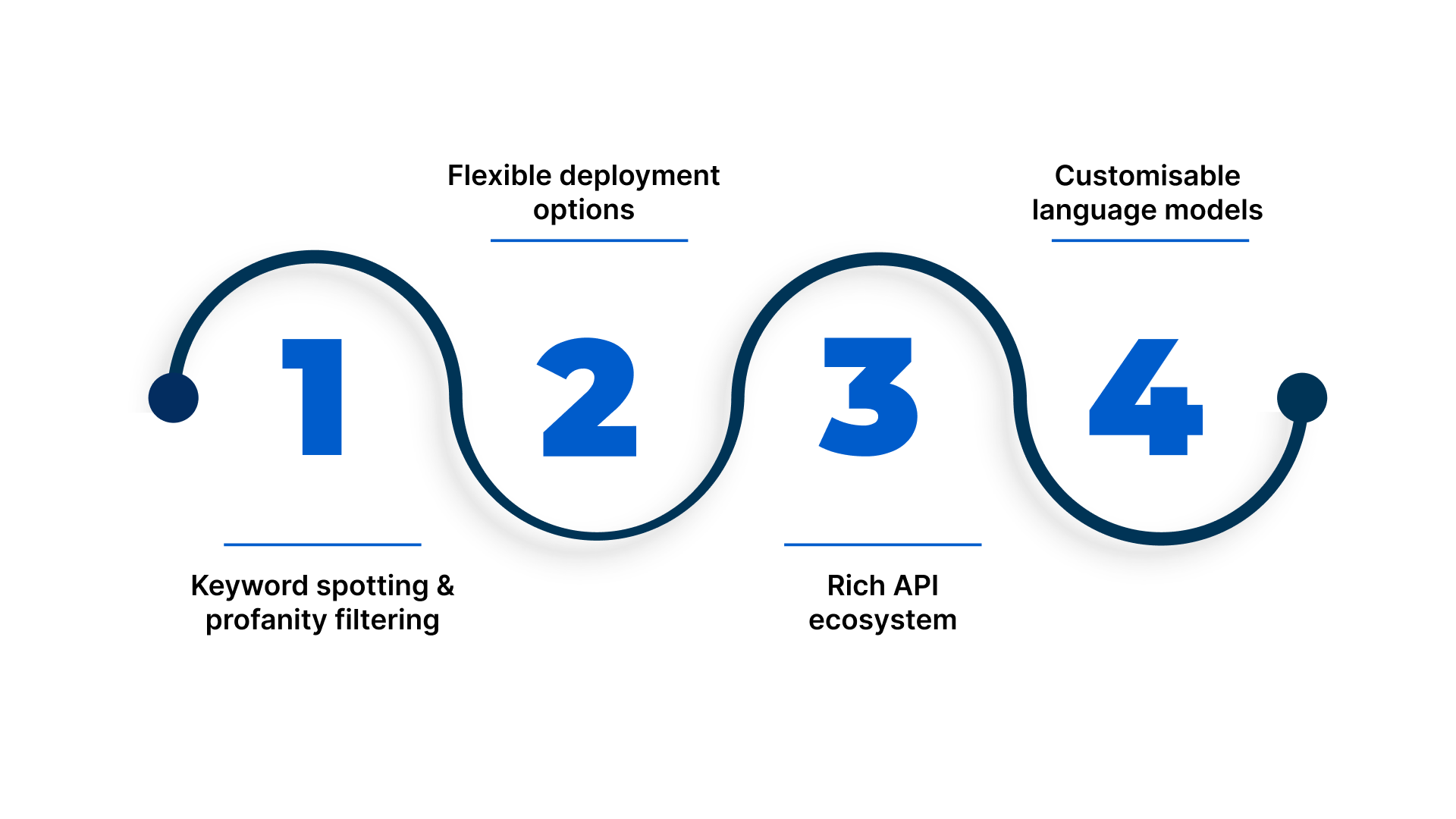
Reverie also delivers enterprise-ready features that go beyond basic transcription:
- Keyword spotting and profanity filtering, enabling precise voice search and content moderation.
- Flexible deployment options, including cloud and on-premise setups to meet regulatory, compliance, and data residency needs.
- Rich API ecosystem with analytics dashboards, detailed usage insights, free credit access via RevUp, and an interactive API playground for rapid validation.
- Customisable language models that can be adapted for domain-specific vocabularies like BFSI or healthcare for improved accuracy in specialised contexts.
This India-focused architecture enables Reverie to handle noisy, telephony-grade audio and mixed-language dialogue more effectively than many generic global models. In markets where accurate transcription of numbers, names, and regional terms matters (such as BFSI call centers) the platform’s emphasis on local speech nuances translates into measurable business value.
With this combination of deep regional language understanding, scalable enterprise features, and developer-friendly tooling, Reverie’s capabilities in 2026 stand out as particularly well-aligned to the demands of Indian businesses seeking production-grade speech recognition.
Deepgram in 2026: Platform Overview and Core Features
Deepgram is a voice AI platform and speech-to-text API provider that enables developers and enterprises to integrate automatic speech recognition (ASR) into real-time and batch workflows. In 2026, its enhanced APIs support advanced transcription, analytics, next-generation voice agents, and expanded multilingual capabilities, benefiting sectors such as customer support, healthcare, media, and conversational AI.
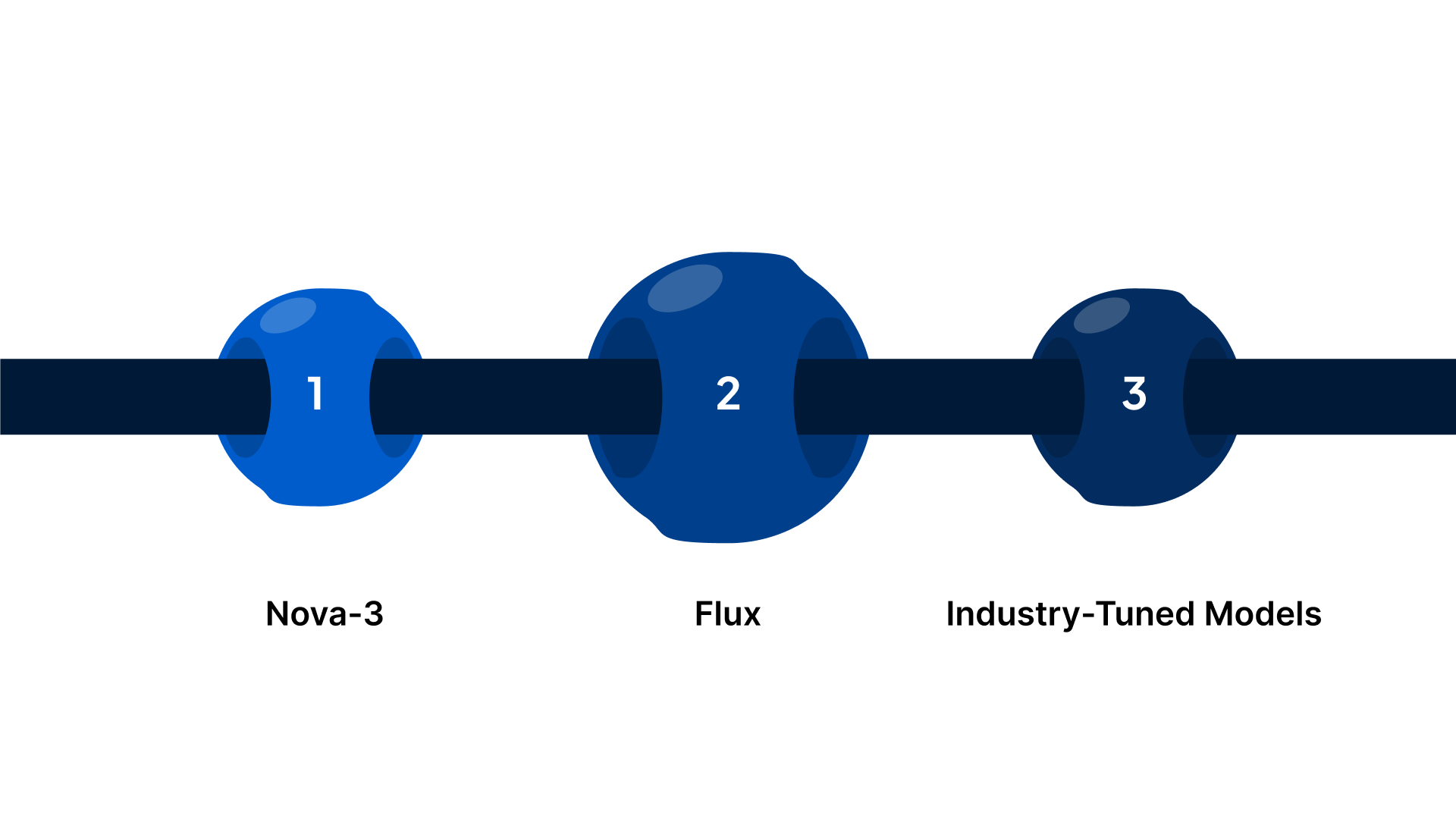
At the core of Deepgram’s offering is a family of models optimised for different scenarios:
- Nova-3: A high-performance ASR model built for production transcription with strong accuracy, noise robustness, and support for global languages, including real-time and recorded audio.
- Flux: A conversational speech recognition model designed specifically for real-time voice agents, with built-in turn detection, low latency, and natural interruption handling to power human-like dialogue experiences.
- Industry-Tuned and Custom models: These allow fine-tuning for domain-specific vocabulary and behaviors (e.g., legal or healthcare contexts).
Deepgram’s speech-to-text API supports 36+ languages and dialects, enabling the development of global applications with multilingual transcription capabilities. Its feature set includes smart formatting (automatic punctuation and capitalisation), speaker diarisation, keyword prompting to boost recognition of critical terms, numeral handling, and redaction for sensitive content.
Also Read: What is Language Translation and How Does It Work
Deepgram vs Reverie: What Makes Them Different?
Deepgram and Reverie solve the same core problem, which is turning speech into usable text, but they approach it from very different starting points. Deepgram is built for global scale, prioritising speed, low latency, and consistency across many languages, which makes it a strong fit for worldwide voice applications.
Reverie, on the other hand, is optimised for India’s linguistic reality, where conversations frequently shift between languages, accents vary widely, and accuracy on names, numbers, and regional phrasing matters more than broad coverage.
Here are some of the key differences between the two:
| Feature / Capability | Deepgram | Reverie |
| Primary focus | Global, enterprise transcription & voice AI | Indian languages & mixed-language speech |
| Languages supported | 36+ global languages & dialects | 11+ Indian languages tailored to regional use |
| Multilingual code-switching | Supported for major languages (10+) via unified model | Designed specifically for Indian mixed speech (e.g., Hindi–English) |
| Real-time streaming | Ultra-low latency with conversational models (Flux) | Real-time transcription with strong Indian language handling |
| Batch transcription | Yes, production-grade | Yes, with telephony and multi-accent support |
| Model customisation | Custom & industry-tuned models | Domain vocabulary adaptation for sectors like BFSI/healthcare |
| Deployment | Cloud, on-premise | Cloud, on-premise |
| Enterprise tooling | Smart formatting, diarisation, redaction, keyword prompting | Analytics, IVR readiness, profanity filtering, API playground and free testing credits |
| Typical use cases | Global contact centers, media transcription, conversational AI | Indian IVR, call centers, voice apps with regional languages |
Also Read: 8 Benefits of a Multi-Language Website
When One Might Be Better Than the Other
Both Deepgram and Reverie offer strong speech-to-text capabilities, but they serve different primary needs. Deepgram is architected for global scale, low latency, and advanced voice AI applications, while Reverie’s India-focused datasets, multilingual regional models, and nuanced handling of mixed speech patterns give it a practical edge for businesses operating in India’s complex linguistic landscape.
Reverie is better suited when:
- Your primary user base speaks Indian languages, mixed languages (Hinglish), or regional dialects.
- You want telephony and call-center transcription that handles Indian accents and noisy audio.
- You require domain-specific language adaptation for sectors like banking, BFSI, healthcare, or government.
- You’re targeting enterprise Indian workflows where performance on nuanced speech patterns matters.Deepgram excels when:
- You need broad language coverage across diverse global markets with consistent tooling.
- You’re building conversational AI or voice agents with ultra-low latency requirements.
- Features like speaker diarisation, keyword prompting, and redaction are critical across varied languages.
Indian enterprises usually prefer Reverie because it is built specifically for India’s multilingual, mixed-language, and telephony-heavy environments. It delivers higher real-world accuracy across regional languages while meeting enterprise scale and deployment needs.
Also Read: Medical Transcription: Revolutionizing Healthcare Through Precision, Technology, and Efficiency
Why Reverie Is Better Suited for Indian Businesses
Reverie is designed specifically for India’s multilingual, mixed-language, and high-volume speech environments. Instead of adapting a global speech engine for Indian use cases, Reverie trains and optimises its Speech-to-Text model on how people in India actually speak across regions, accents, and real call conditions.
This India-first approach makes a measurable difference for enterprises working with customer conversations, IVR systems, and voice-led applications where accuracy on numbers, names, and code-switched speech directly impacts outcomes.
What gives Reverie a clear advantage in India:
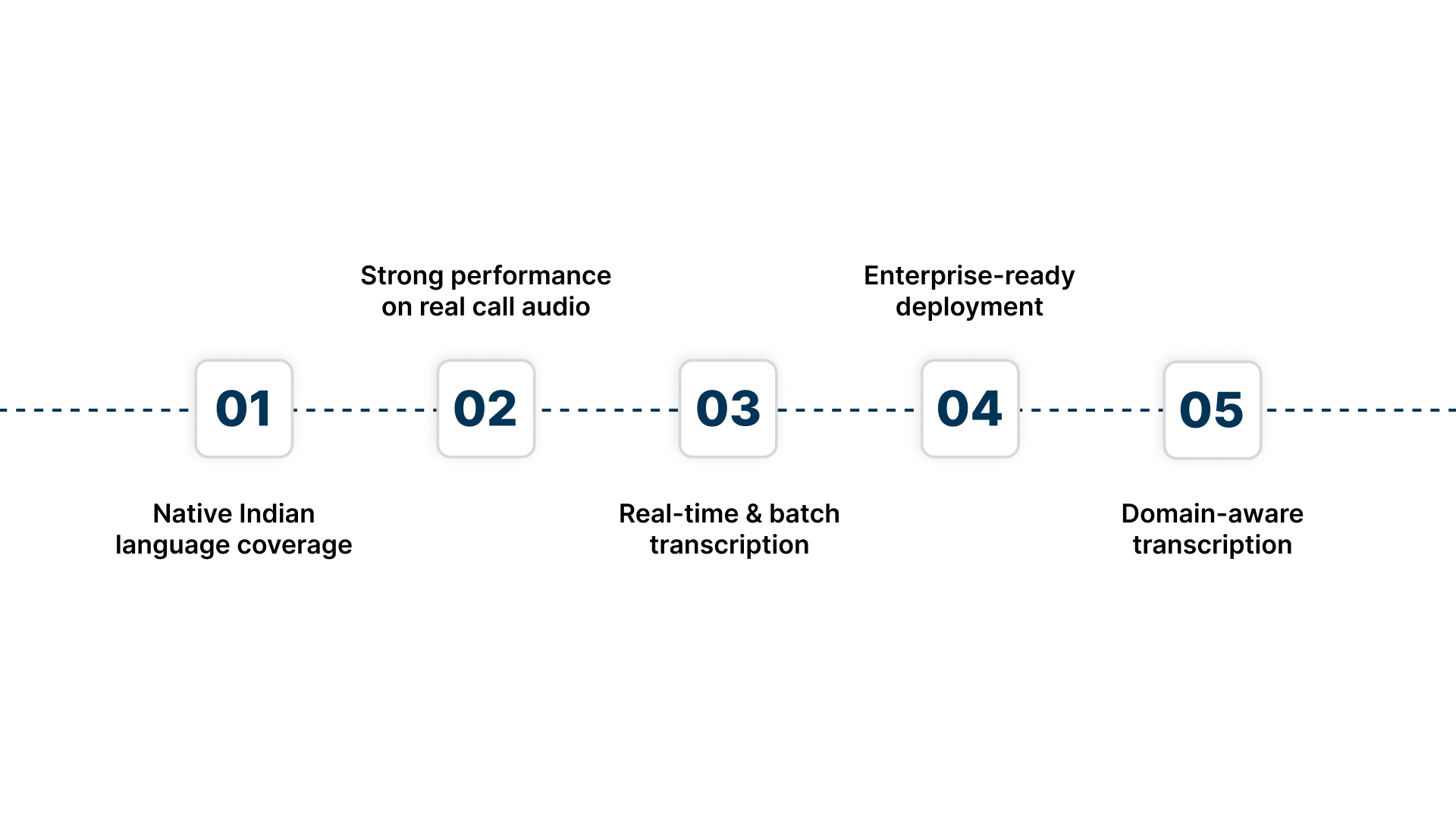
- Native Indian language coverage: Supports 11+ Indian languages with dedicated models, not generic multilingual layers.
- Strong performance on real call audio: Built to handle telephony-grade input, background noise, and mixed Hindi-English or regional speech.
- Real-time and batch transcription: Works equally well for live calls, voice bots, IVR flows, and large volumes of recorded audio.
- Enterprise-ready deployment: Available on cloud or on-premise to meet data residency, compliance, and security requirements common in BFSI.
- Domain-aware transcription: Adapts to industry-specific vocabulary and accurately recognises numbers and Indian names, reducing post-processing effort.
For Indian enterprises evaluating Deepgram vs Reverie, the distinction is clear: Deepgram is optimised for global speech patterns, while Reverie is optimised for India’s linguistic complexity and operational scale.
Conclusion
Selecting a Speech-to-Text API is ultimately a business decision, not a popularity contest. The right choice depends on how well the system understands your users, your audio conditions, and the realities of operating at scale.
For Indian enterprises, Reverie stands out by delivering consistent transcription quality in multilingual, code-switched, and noisy environments, where accuracy on numbers, names, and intent truly matters. Its ability to support both real-time and large-volume workflows, combined with enterprise-friendly deployment options, makes it easier to move from evaluation to production with confidence.
If your goal is to turn spoken conversations into reliable, actionable data across India, Reverie offers a practical path forward.
Get started today with Reverie and test it in minutes. Sign up now!
FAQs
1. Can Reverie accurately recognise numbers across languages?
Yes. The API is trained to recognise numbers spoken in English, Indian languages, and mixed speech (for example, switching between Hindi and English), which is critical for use cases like payments, account details, and call-center conversations.
2. Does it support Hinglish and code-switched speech?
Reverie’s models are trained on real conversational data from India, enabling them to understand natural language switching within the same sentence rather than treating it as an error or fragmented input.
3. Does it work well with call-center and IVR audio?
Yes. Reverie’s Speech-to-Text API is designed to work reliably with IVR and call-center audio, including compressed, noisy, or low-fidelity recordings commonly found in enterprise telephony systems.
4. Can transcription be customised for specific industries?
Yes. The API supports domain-specific language packs and vocabulary tuning, allowing businesses in BFSI, healthcare, or government to improve recognition of specialised terms, names, and phrases.
5. What happens after the trial if a business wants to scale usage?
Teams can move seamlessly from evaluation to production by increasing usage limits, enabling advanced configurations, and choosing cloud or on-premise deployment, without changing APIs or re-integrating their systems.
