
Did you know the global speech-to-text market is expected to grow from roughly $3.8 million in 2024 to more than $8.5 million by 2030? This reflects how rapidly enterprises are adopting voice recognition.
If your teams handle customer calls, IVR audio, or voice notes, you already know how much valuable information exists within those recordings. Turning that audio into accurate, usable text at scale is challenging, and in India, mixed languages, accents, and noisy environments make it even harder.
In this blog, you’ll explore the 10 best software solutions for voice recognition in 2026, focusing on accuracy, Indian language support, integration flexibility, and business readiness.
At a Glance
- Built for Real Audio: Enterprise voice recognition must handle noisy calls, overlapping speech, and telephony constraints, not studio-quality recordings.
- Language Claims Need Validation: Listed language support is not enough. Real-world testing with accents, mixed speech, and domain terms determines actual usability.
- Integration Drives Adoption: Well-documented APIs and SDKs reduce engineering effort and enable faster rollout across IVR, apps, and analytics systems.
- Customisation Impacts Accuracy: Domain vocabularies and model tuning are critical in regulated, terminology-heavy industries.
- Scalability is a Design Requirement: Systems must maintain consistent latency and accuracy during peak traffic without manual intervention.
What is Voice Recognition Software?
Voice recognition software, also known as speech-to-text, is a system that automatically converts spoken audio into written text using automatic speech recognition (ASR). In enterprise environments, this capability is delivered through APIs and SDKs that can be embedded into applications, IVR systems, bots, and analytics platforms.
Unlike consumer dictation tools, enterprise voice recognition software must support real-time transcription, batch processing, speaker separation, and domain-specific vocabulary. It also needs to integrate seamlessly into existing digital workflows while meeting latency, accuracy, and security requirements.
To maximise the benefits of voice recognition software, it’s essential to understand which features have the most direct impact on performance, accuracy, and scalability.
Key Features to Look for in Voice Recognition Software
Choosing the right voice recognition software requires a keen focus on capabilities that match your business’s scale, workflow complexity, and regulatory needs. Here are the essential features you should evaluate:
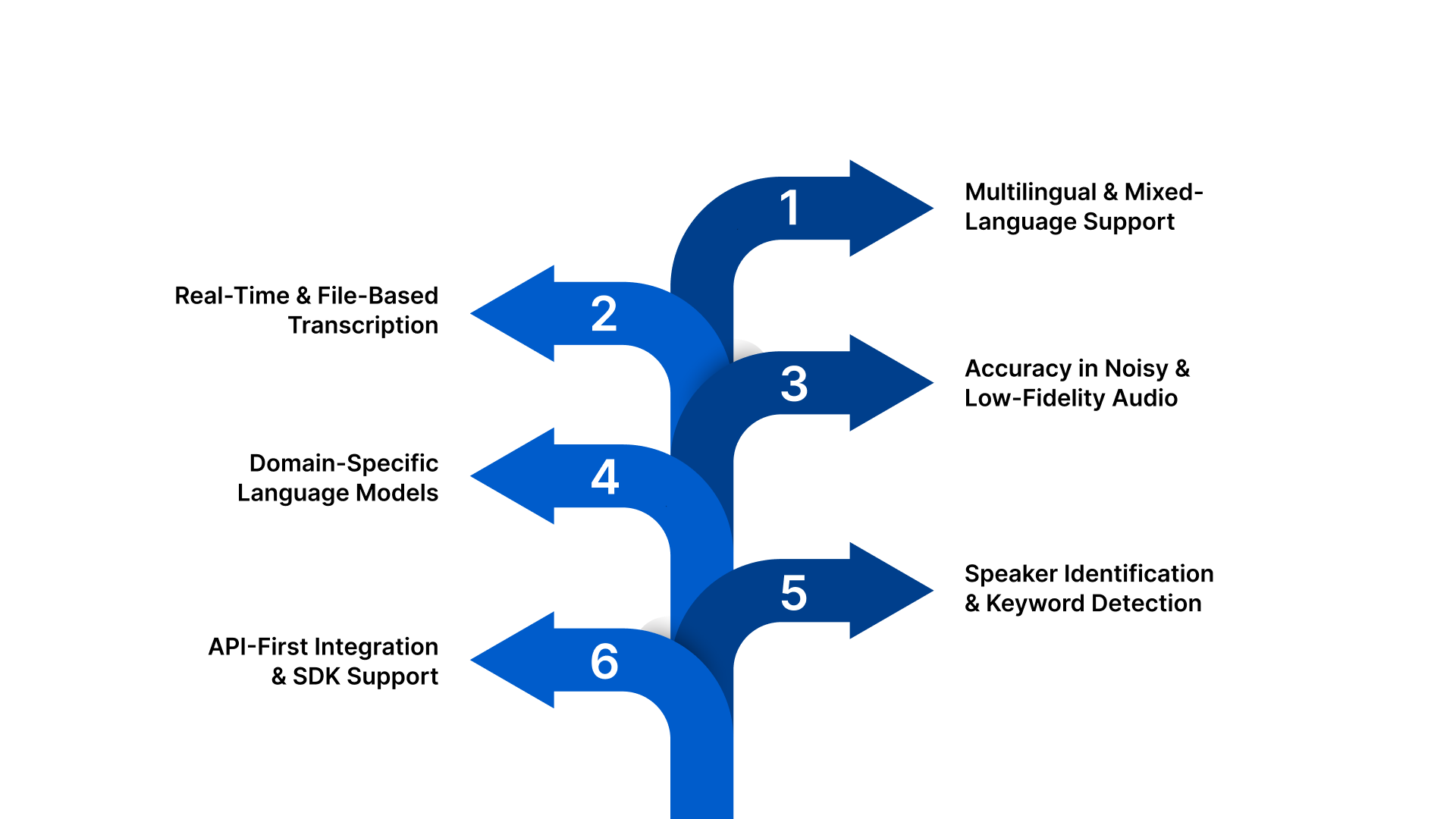
1. Multilingual and Mixed-Language Support: The software should support major Indian languages and handle mixed-language speech, allowing users to switch between English and regional languages within the same sentence. This is critical for customer calls, IVR systems, and voice-enabled applications in India.
2. Real-Time and File-Based Transcription: Enterprises often need both live call transcription and voice bots, as well as batch processing for recorded meetings or call archives. A single platform should support streaming and file uploads without separate tools or workflows.
3. Accuracy in Noisy and Low-Fidelity Audio: Real-world audio is rarely clean. Voice recognition software must work effectively with background noise, overlapping speech, and low-quality IVR or telephony audio. Consistent accuracy in these conditions separates enterprise-grade systems from basic tools.
4. Domain-Specific Language Models: Generic language models struggle with industry terminology. The ability to customise vocabulary for domains such as banking, healthcare, legal, or automotive significantly improves transcription quality and usability.
5. Speaker Identification and Keyword Detection: Identifying different speakers in a conversation helps with analysis, compliance, and review. Keyword spotting enables businesses to track important phrases, triggers, or compliance-related terms within large volumes of audio data.
6. API-First Integration and SDK Support: Enterprise voice recognition software should be accessible through well-documented APIs and SDKs for web, mobile, and backend systems. This ensures faster integration into applications, IVR platforms, and analytics pipelines.
Choose voice recognition that handles Indian accents and noise
Test how voice recognition performs on real Indian audio across languages and workflows. Teams report up to 97% reduction in development time with Reverie STT.
Also Read: 5 Key Uses of Speech-to-Text Transcription in Business
With these features in mind, it’s time to explore the top software for voice recognition available in 2026.
Top 10 Software for Voice Recognition in 2026
Voice recognition requirements vary across industries, from real-time voice input to multilingual customer call analysis. Accuracy, language coverage, latency, and integration depth are critical factors in selecting the right solution for enterprise workflows.
Here are the top software for voice recognition to consider in 2026:
1. Reverie Speech-to-Text API
Reverie provides a unified voice API platform for Indian languages. The Speech-to-Text API converts spoken audio into accurate text across 11+ Indian languages, while the Text-to-Speech API converts written content into natural-sounding speech. Both are designed for India’s multilingual and mixed-language environments.
Key Features:
- Indian language support: Covers 11+ Indian languages, including Hindi, Tamil, Telugu, Kannada, Bengali, and Marathi for wide regional coverage.
- Real-time and batch transcription: Handles live calls, IVR audio, meetings, and prerecorded files.
- Flexible deployment: Offers cloud or on-premise setups to meet compliance, data residency, and security requirements.
- Custom vocabulary and formatting: Supports domain-specific terms and adds punctuation for clean, usable transcripts.
- Integrated text-to-speech engine: Generates natural-sounding voices for IVR, voice assistants, accessibility, and audio content creation.
Best Suited For: Enterprises, startups, and public-sector organisations that need reliable, multilingual STT and TTS capabilities for customer support, BFSI, e-commerce, education, healthcare, IVR systems, and voice-first apps.
Benchmark Hinglish and Indian-language transcripts in minutes. Start building with Reverie’s voice APIs today!
2. Speechmatics
Speechmatics offers an automatic speech recognition engine built for accurate transcription across multiple languages and deployment environments. It supports both live and recorded audio and is designed to handle diverse accents and real-world speech conditions, making it suitable for enterprise transcription workflows.
Key Features
- Broad language coverage: Accurately transcribes speech across multiple global languages and dialects.
- Real-time & batch transcription: Processes both live audio streams and large prerecorded recordings seamlessly.
- Customisation: Adapts the engine to domain-specific vocabulary for higher transcription accuracy.
- Flexible deployment: Can be deployed on cloud, edge, or on-premise environments to suit enterprise needs.
Best Suited For: Media companies, enterprise workflows, multilingual transcription at scale, and technology teams embedding ASR into platforms.
3. Voicegain
Voicegain is an enterprise‑grade voice recognition platform that offers highly accurate automatic speech recognition (ASR) with both real‑time and batch capabilities. Built for developers and businesses, it enables seamless integration of voice transcription and conversational AI into applications, contact centres, IVR systems, and voice assistants.
Key Features
- Real‑time & batch transcription: Supports low‑latency live audio capture and bulk file transcription.
- Conversational AI support: Enables voicebot and conversational workflows with intent detection.
- Custom models & domain tuning: Allows training for industry‑specific vocabulary and accents.
- Flexible deployment: Options for cloud, hybrid, and on‑premise installations to meet enterprise requirements.
- Robust API & SDKs: Developer‑friendly REST APIs and SDKs for web, mobile, and backend systems.
Best Suited For: Enterprises and technology teams building voice‑enabled applications, conversational AI systems, multilingual voice analytics, and scalable ASR pipelines.
4. Google Cloud Speech-to-Text API
Google Cloud Speech-to-Text is a widely used API that converts audio into text using neural network models. It supports both real-time streaming and asynchronous transcription across a broad set of global languages.
Key Features:
- Global language coverage: Supports more than 125 languages and variants for broad multilingual use.
- Streaming and batch transcription: Handles both real-time audio and prerecorded files.
- Automatic punctuation: Adds commas, full stops, and basic formatting for readable transcripts.
- Word-level timestamps: Provides time-aligned word offsets for syncing transcripts with audio or video.
- Speaker diarisation: Detects and separates different speakers during multi-person conversations.
Best Suited For: Global and multilingual applications, English-first workflows, media captioning, video subtitling, and SaaS platforms that already use Google Cloud.
5. Microsoft Azure Speech
Azure Speech is part of Microsoft’s AI suite and offers both real-time and batch transcription. It also supports custom speech models, enabling enterprises to improve accuracy for domain-specific terminology.
Key Features:
- Real-time and batch transcription: Supports live audio and large archived recordings.
- Custom speech models: They allow fine-tuning for domain-specific terminology and improvements in accuracy.
- Broad language support: Offers many languages, depending on regional availability.
- Comprehensive SDKs: Provides integrations for web, mobile, and backend systems.
- REST API for flexible workflows: Enables simple embedding into enterprise platforms and internal tools.
Best Suited For: Enterprises working within the Microsoft/Azure ecosystem, organisations needing domain-adapted models, and teams that require both real-time and batch processing.
6. Amazon Transcribe
AWS Transcribe is Amazon’s cloud-native speech-to-text service, designed for deep integration within AWS ecosystems. It offers transcription services suitable for both real-time streaming and batch workloads.
Key Features:
- Real-time streaming transcription: Captures live audio input for instant text output.
- Asynchronous batch transcription: Handles long audio recordings and large workloads efficiently.
- Broad codec and file support: Ingests a wide range of audio formats used in enterprise environments.
- Tight integration with AWS services: Works smoothly with S3, Lambda, Kinesis, and more.
- Scalable for high-volume usage: Uses AWS cloud performance to manage enterprise-scale workloads.
Best Suited For: Organisations heavily invested in AWS, SaaS platforms, and teams needing scalable transcription inside an existing cloud pipeline.
7. Deepgram
Deepgram provides a Voice-AI platform that includes speech-to-text, text-to-speech, and voice agent capabilities. Its STT API is designed for high-speed processing and enterprise-scale voice workloads.
Key Features:
- Real-time and async transcription: Suitable for live streaming and large prerecorded datasets.
- Cloud and self-host deployments: Offers flexibility for organisations with specific infra or compliance needs.
- High-volume scalability: Built to support large enterprise workloads.
- Unified voice AI capabilities: Includes STT, TTS, voice agents, and audio intelligence tools in one platform.
- Custom model options: Provides different model types tailored to use cases and accuracy needs.
Best Suited For: Companies building voice-enabled products, teams that need scalable real-time transcription, and enterprises requiring flexible deployment models or end-to-end voice pipelines.
Also read: Top 5 Deepgram Alternatives for Speech-to-Text API
8. LumenVox Speech Engine
LumenVox Speech Engine is a flexible speech recognition platform designed for enterprise voice applications, including IVR, call centre automation, and telephony systems. It focuses on high accuracy, predictable performance, and secure deployment options suited for regulated industries and large contact‑intensive operations.
Key Features
- Real‑time voice recognition: Captures live speech for telecommunications and interactive voice response.
- Custom language/dialect support: Tailors models for specialised vocabularies and regional speech patterns.
- Telephony & IVR readiness: Built‑in support for telephony standards and protocols, enabling seamless integration with call platforms.
- On‑premise & cloud deployment: Enterprise options for secure, compliant installations.
- Detailed logging & diagnostics: Provides tools for performance tuning and operational insights.
Best Suited For: Contact centres, BFSI, government and public sector organisations, telecom operators, and enterprises needing IVR and telephony‑centric voice recognition.
9. AssemblyAI
AssemblyAI offers modern deep-learning-based speech recognition through a simple API. Their models focus on fast transcription (batch and real-time), good accuracy, and a rich set of transcription-enhancing features.
Key Features:
- Real-time and batch transcription: Supports both live audio streams and prerecorded files for different workflow needs.
- Speaker diarisation: Separates multiple speakers in meetings, calls, or interviews.
- Automatic punctuation and formatting: Produces clean, readable transcripts without manual editing.
- Word-level timestamps: Helps align transcripts with audio or video for reviews and editing.
- Wide input format support: Accepts many audio and video formats with minimal pre-processing.
Best Suited For: Media teams, podcast workflows, product teams processing large volumes of audio or video, and applications needing fast turnaround for recorded content.
10. IBM Watson Speech to Text
IBM Watson Speech to Text offers enterprise-grade ASR with support for real-time streaming and batch uploads, customisable speech and domain models, and reliable data governance and compliance.
Key Features:
- Real-time and batch transcription: Supports WebSocket streaming and HTTP-based file uploads.
- Custom speech models and vocabulary tuning: Improves accuracy for industry-specific terminology.
- Speaker diarisation: Detects and separates speakers in multi-voice audio.
- Smart formatting: Adds punctuation, confidence scores, and metadata to make transcripts production-ready.
- Flexible deployment options: Available as public cloud, private cloud, hybrid, or fully on-prem.
Best Suited For: BFSI, healthcare, government, and other regulated sectors that require secure transcription, custom domain adaptation, and on-prem infrastructure.
Also Read: How Reverie’s Speech-to-Text API is Reshaping Businesses in India
Reduce Operational Costs with Reverie Speech-to-Text
Save up to 62% using Reverie’s multilingual Speech-to-Text APIs.
Each platform brings different strengths, but not every solution fits the realities of Indian speech, enterprise scale, and complex system integration. Let’s look at how to evaluate the right option for your business.
How to Choose the Right Software for Voice Recognition
Voice recognition software should be evaluated in the context of how it will be used, not just what it claims to support. Factors such as real user speech, expected workloads, and compatibility with your current systems play a central role in determining the right fit.
Here are a few key areas to consider before making a decision:
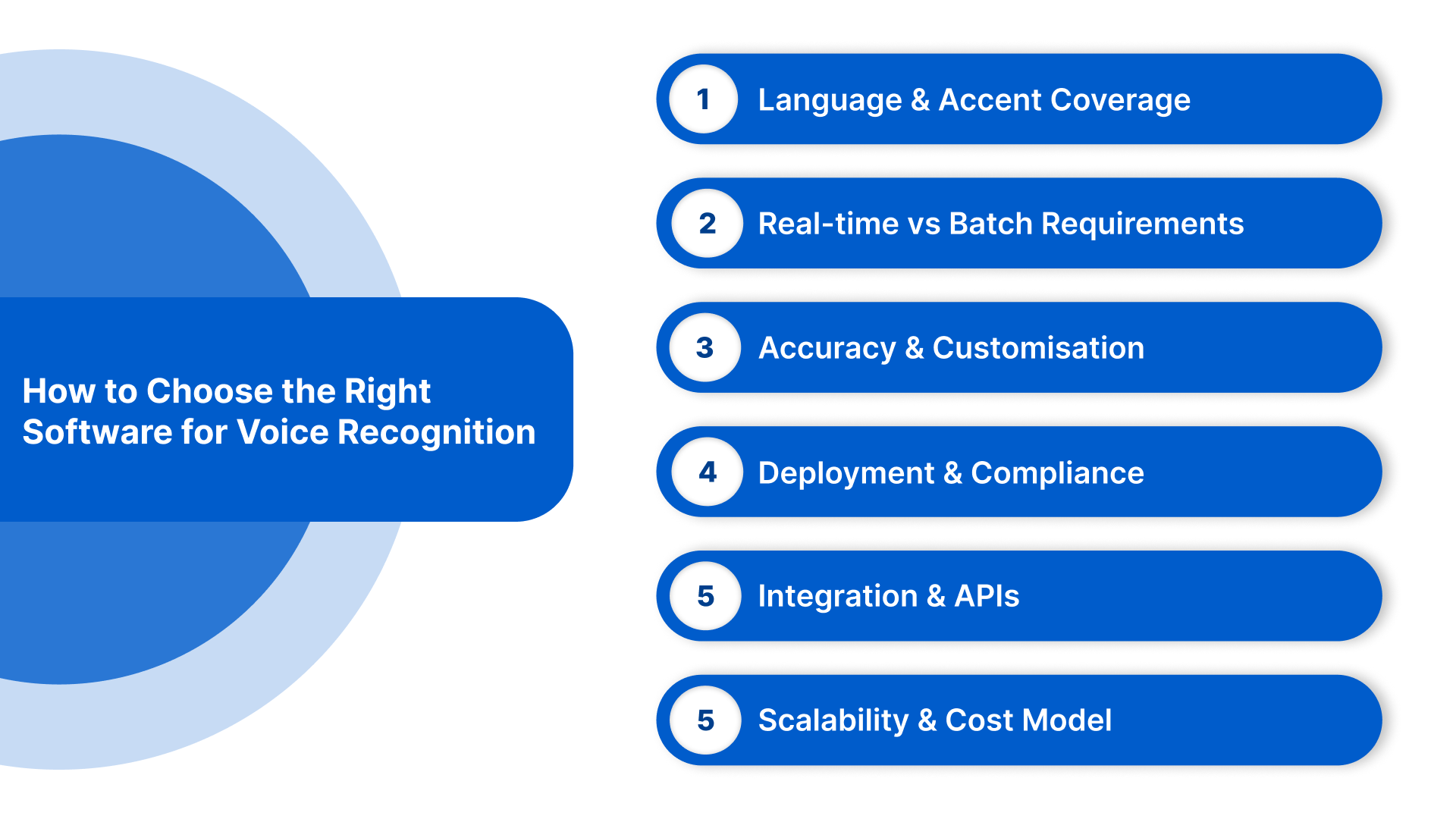
- Language and Accent Coverage: If your users speak Indian languages or mixed-language speech such as Hinglish, verify real-world accuracy, not just listed support. Test with regional accents, code-switching, and domain terms.
- Real-time vs Batch Requirements: Define whether your use case needs live transcription for calls and IVR, offline processing for recordings, or both. Not all platforms perform equally well across these modes.
- Accuracy and Customisation: Check support for custom vocabularies, domain tuning, and model adaptation. This matters for BFSI, healthcare, legal, and support workflows with specialised terminology.
- Deployment and Compliance: Assess cloud, hybrid, or on-premise options based on data residency, security policies, and regulatory needs. Public-sector and regulated industries often require tighter control.
- Integration and APIs: Review API maturity, SDK availability, and compatibility with your existing stack, including contact centre platforms, CRMs, and analytics pipelines.
- Scalability and Cost Model: Ensure the platform can handle peak loads without performance drops. Compare pricing based on minutes processed, concurrent streams, and add-on features.
Also Read: What is ASR: Full Form and Its Significance in Voice Technology
A structured evaluation across these factors helps narrow down platforms that are technically suitable and operationally practical for your business.
Final Thoughts
Choosing the right voice recognition software is ultimately about alignment with your business context, not feature count. Accuracy across real user speech, support for scale, and fit with existing systems matter far more than generic language claims or brand popularity.
Among these, Reverie’s Speech-to-Text API stands out for Indian enterprises that need dependable multilingual transcription. It supports 11 Indian languages, handles mixed-language speech, and offers flexible real-time and batch processing. These capabilities help teams implement context-aware, scalable, voice-search- and voice-driven workflows that align with enterprise security and compliance needs.
Discover how Reverie’s Speech-to-Text API can deliver accurate transcription for your voice search and workflow systems. Sign up to explore multilingual voice solutions built specifically for Indian enterprises.
FAQs
1. How does voice recognition performance change with telephony-grade audio?
Telephony audio often has limited bandwidth and compression artifacts. Enterprise-grade voice recognition software is trained on narrowband audio, handles packet loss, and applies acoustic normalisation to maintain transcription accuracy during IVR calls and contact centre conversations.
2. Can voice recognition systems be audited for regulatory or legal use cases?
Yes. Many enterprise platforms provide word-level timestamps, confidence scores, speaker labels, and immutable logs. These outputs help support audits, dispute resolution, and compliance checks in BFSI, healthcare, and government workflows.
3. What role does language model adaptation play after deployment?
Post-deployment adaptation allows systems to learn from real usage patterns. By updating vocabularies and language models with new terms, organisations can reduce recurring errors caused by evolving product names, policies, or regional expressions.
4. How do enterprises validate accuracy before full-scale rollout?
Most teams run pilot evaluations using historical call recordings and live traffic samples. Accuracy is measured across accents, noise levels, and code-switching scenarios to ensure the system performs consistently under production conditions.
5. Is voice recognition suitable for analytics beyond transcription?
Yes. Once speech is converted into structured text, it can feed sentiment analysis, keyword tracking, compliance checks, and search indexing, enabling deeper insights from large volumes of voice data across business operations.
